Debugging HyperZ and fixing a radeon drm linux kernel module
It was only a few days ago I have finished debugging a really heavy bug making as big of a mesa performance hit in the userland radeon driver that it became a news article on Phoronix. Back then while still on the heavy journey for getting my performance back I saw HyperZ was also not enabled for me, but if I enable it I gain 10-15% more performance - and an unplayable 3D screen.
On the original blog post I have also written about how to troubleshoot a performance issue generally, but what to do if you know about a performance increasing functionality - just you see it destroys the 3D picture?
Read on if you are interested in linux graphics internals once again ;-)
Introducing the problem
If you have an old radeon 3D card that is served by the r300 driver, you do not get HYPERZ enabled. For starters this is an optimization technique on the GPU and as you can see it can give you a bit of a boost in perfomance while it should be completely transparent to the programs.
Most new cards have this feature turned on by default from r600 and onwards, but for r300 you need to turn it on yourself using an environment variable because is was never really and completely tested.
When this is turned on, I measure +2-3 FPS in Extreme Tux Racer - a classic open source linux game. That seems small but it is nearly 10% and more heavy games and programs can actually gain a bit more performance!

To start glxgears with HyperZ you do this:
RADEON_HYPERZ=1 glxgears
Or you can just export RADEON_HYPERZ=1 so all programs from the terminal or
shell session do have it when started later.
This is what the app named glxgears looks like:
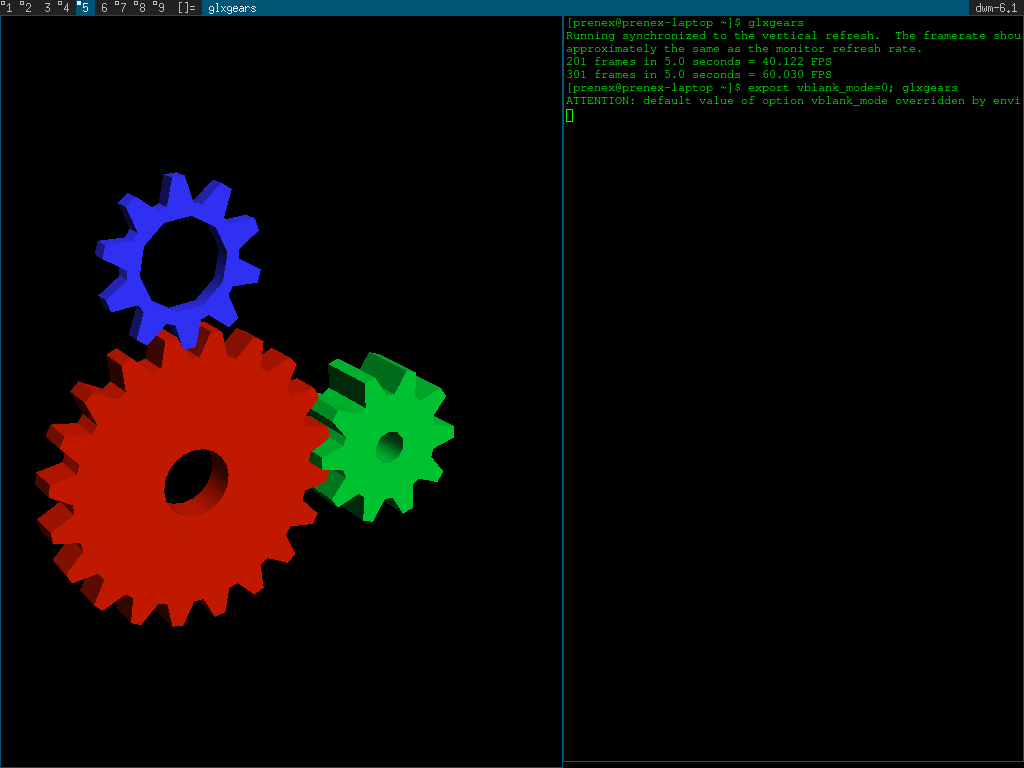
If I turn the wheels so I see the smallest of them I can get max performance around 370 FPS in this simple linux test app. We should boost this a bit!
This is how it looked with the HyperZ technology enabled however:
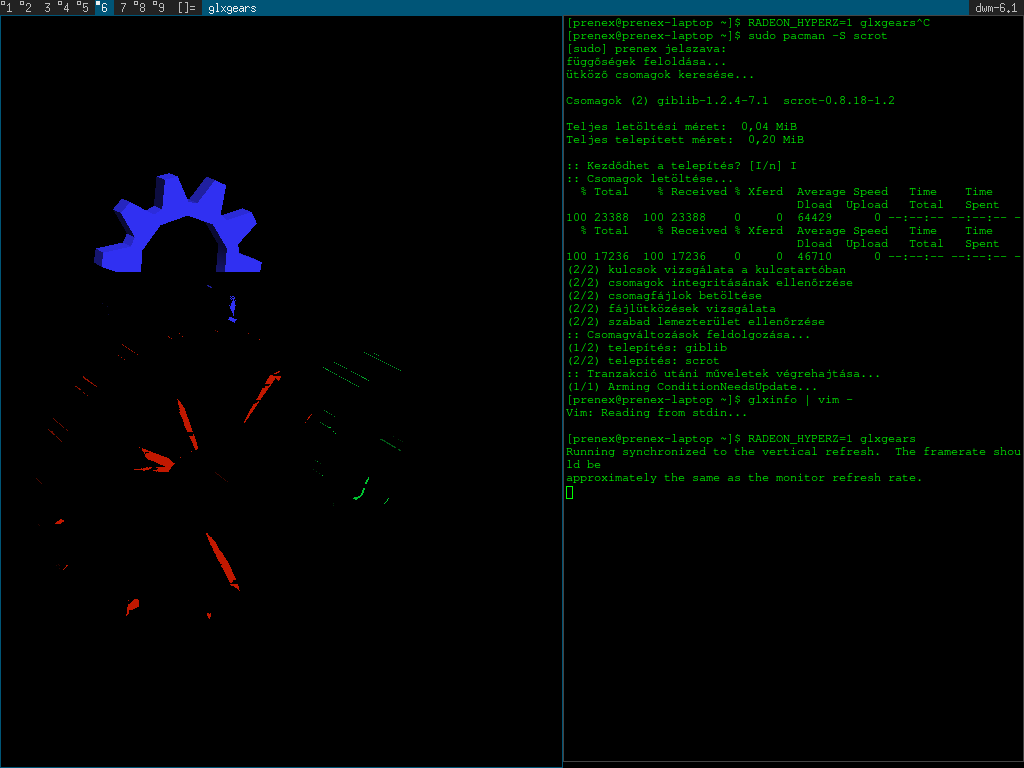
Quite a bad sight is not it? However if I position the gears the same way I can max out around 450-460 FPS which is nearly 100 FPS more peformance! The only problem with that good performance gain is that... come on! Seriously you cannot play or use 3D applications with half of the screen showing up badly in glitches! Surely this is unusable even though fast.
If you ask me, we should get this working if possible! Our card originally do support this feature so we should get this gain out of it, while not having any glitches!
But how should we approach this problem? This was not a slowdown that we can just profile using profilers, neither this ever worked on my machine so there is just no way to "bisect" when it started to go wrong! Just read on! We will fix HyperZ on my Mobility Radeon Xpress 200M card - which is basically an r300!
If you want to see all the details and trials look here for my bug report!
The strategy
We might not have any earlier working version never, neither we do have a way to use profilers to highlight problematic areas, but we actually have a much better "hint" for what the problem is: Yes! It is HyperZ itself or at least the implementation of HyperZ in the driver likely! It can be that the error is not there directly, but it serves as a starting point for us!
What is the Zbuffer?
First of all I should at least give a rough introduction to all the various technologies used here because I do knew about some of them - and also had to learn about a lot of them myself. To fix an error like this, you better get your way around trying to collect all possible information about the feature you are trying to fix. One however cannot barely explain HyperZ if the reader does not know about what ZBuffer itself is originally.
ZBuffer is needed to solve which parts of an object should show. This is the fast and easy explanation of why it exists.
Imagine the following scene (top-down view):
┌─────────────────────────────────────────────────────────┐
│ * light bulb ╔═════════╗ │
│ ║Furniture║ │
│ ║ ║ │
│ Viewer ║ ║ │
│ ║ ║ │
│/ -> ║ ║ │
│ ┌────────┐ ║ ║ │
│ │ Sofa │ ║ ║ │
│ ├────────┤ ║ ║ │
│ └────────┘ ╚═════════╝ │
└─────────────────────────────────────────────────────────┘
This is a top-down view of a room in which the viewer stands near the door. How would you draw this for an interior design program (or just a game)?
In real life the light that comes from the light bulb would shine the various physical parts of our world which would reflect the light in all directions and only in the wavelengths that the material of the object reflects - giving not only light, but also colors. God does not need a giant computer so this is just easy-peasy for him, but we humans are not having skills like that and our simulated computer worlds run on slow machines compared to the real world. In short there is no way to just render (display) a screen like this and we use some tricks - except for Ray tracing, which actually simulates all this above!
What we do instead is that we make small 3D triangles, project them onto the screen using perspective projection techniques similar to what a painter or and artist is doing and we do not even use wavelengths for colors, just set a triangle to be red - or using trickery we span and map a "texture" on its plane so that the triangle is not only coloured, but show some detail.
So great so far, all games and 3D apps basically just work like this from the Quake and onwards (and even earlier sometimes) and this is what your 3D card is accelerating. But there is one big problem with this! We should paint out every object using perspective, but in which order should we do so?
Look at this picture I have modelled in Blender3D (clearly looking good):

Now look at this one from the same room and clearly wrong:

Do you see what I did? Actually even if you think you do, you do not know maybe that I manually had to work for this to get rendered this badly, but what I mean is that if you just draw everything in 3D using the above tricks, you really get into problems when you draw some farther away object "on top" of the one that is closer to the camera or the viewpoint.
Also this is not the worst possible scenario actually, because guess what is happening if you are drawing in a more different order.
Drawing the walls of the room the last for example...

This is not a very pleasant thing to see and clearly not something you see in real life so your users will freak out and say your product is shit in case that you are presenting these bad pictures for them.
So what is a fast solution to this? As you might be wondering we can of course order the objects draw calls in the order of their distance from the camera. This means that in our case we draw the sofa later than the furniture in the background because the sofa is more closer to the camera, but what about the room? How do you define your distance from the "room"? Maybe you just add a pretty simple "hack" that "rooms / backgrounds are always drawn the first time" or maybe you are even smarter and you separate rooms into their "walls".
But what if you have two people hugging each other? Will you render Amrice or Richie first? Because they are hugging each other there will be an ordering problem in both ways because their hands are around each other!
You can speculate that you will then seperate the hands as seperate objects to
draw and very early you will end up only having convex meshes and a task to
properly order them from their camera distance. Also sorting meshes from back
to the front is not an easy task as sorting algorithms are usually n(log n)
fast only in speed so you quite early on get a very big slowdown. Of course
you can try geometric near-linear sorting using hashing like prenex-turbo
sorting methods and such things based on circular sweeping and hashing the
objects but those methods still work linearly only if few of the vertices fall
onto the same polar-coordinates and have a much bigger overhead than a normal
merge or quicksort or whatever normal thing so need a strong hardware.
But hey! We are sorting every small convex object now, why we do not just go even more deeper and sort even smaller things? Like every pixel after they get to be projected onto the 2D screen could be sorted maybe! That just sound even more time consuming on the first sight but it is a very neat trick, because all you need to do is to store a "depth value" for each of the pixels while drawing!
This is what kind of image we get like this:

Just store the Z distance of that pixel from the camera so that we do not need to order the objects anymore, just make a comparison with already saved Z-data of the already existing pixels and update them accordingly. With this, you do not overwrite pixels that have been drawn earlier, but have a closer Z value!
This way you need two buffers while you are drawing each frame in 3D:
+-----------+
| Z (depth) |
| Buf |
+-----------+
+
+-----------+
| Color |
| Buf |
+-----------+
One might speculate that we do not really need two buffers as all we need to create is some extra per-pixel channels. We already have an alpha channel for example so we are already "RGBA" why do not just add one more channel for Z? That would be a really bad idea, because we only need this Z usually while the screen is being drawn, but never any later so it would be really bad. Also the really smart ones maybe start to ask themselves now, that I have mentioned the alpha channel: "but what about half-transparent objects" like water? Hohohoo! In case we do those kind of stuff we need to order them once again because there might be a car sunk into shallow water with green colored window so we are having a big hard time to solve these. Actually overly general big 3D engines like Unity3D solve these by using the midpoints and clever sorting of the objects and this indeed leads to glitches when things just disappear. I have no idea what Godot 3.1 does, but I like that more as it is open source.
Now Imagine that if you are having 1024x768, you are already having around 700k memory just to hold the screen you are drawing onto, but in case you also add this Z-buffer (and practically everyone does) you get an other near-same sized memory area on your GPU. This memory might be actually not even on the video card as it might be a mobile card that shares on the main system memory so not only it is more GPU memory usage, but reading from this memory while writing to each pixel color is a lot of memory bandwith usage and a lot of operations too. Do not get me wrong, this is still much-much better usually than ordering objects to draw, because this is a clearly linear and optimized operation of course.
Actually HyperZ is all about optimizing this even further by attacking this Z-value comparison to have a bit faster speed and less bandwith need!
There is also early-Z rejection which happens if there is also a Z unit on the top of the pipeline and we can reject objects to draw much earlier than all the shading and costly things happen. The weird thing is that to get the most pixels rejected early now your best bet became to actually render the scene in completely the opposite direction than how we tried above before the introduction of the Z-buffer. Now having early-Z reject in GPUs we better first render the closest stuff so that everything else can be rejected by the early Z mechanisms ("Z on top" in the docs and driver). A good example is when you are facing a wall in a game that hides a whole city: you get a big amound of extra frame rate if you first render this wall and only later draw all the other buildings of the city because the latter will be really cheap and just completely rejected as early as possible!
Btw do not get me started on the minecraft-style very low poly 3D examples as I am not a 3D artist and even though I can make much-much better things if I spend time on it, this is just there to illustrate the ideas.
You can download the blend file if you really want to of course. CC0 haha!
What is HyperZ
Okay finally we are closing on! How to make the above Z-test faster? There are of course a whole lot of ideas and one implementation for such optimized Z is coming from ATI. They named this technology idea to be HyperZ not only as the Z-testing is "Hyper-fast", but also because the idea itself.
According to random tales on the internet, HyperZ is:
- Fast Z-buffer clearing
- Hierarchical Z-buffering
- Lossless Z-buffer compression
HiZ
Let us start with the Hiearchical Z-buffer because that is the most easy to comprehend using the above presented Z-testing schemes in my opinion. This is also called "HiZ" in the various technical and marketing docs for radeon and yes I really guess this is what named "HyperZ" after all - but I only guess.
So what is the name hierarchical refer to? Basically you do a quite usual kind of space partitioning trick to go around the need to calculate values for the the whole number of stored Z-values when drawing. Alongside storing all the Z values just like presented before, we also store a much smaller buffer where you split an image into multiple "tiles" evenly tiling the screen. You can then save for each of these tiles what is the most close Z-value for all the already drawn pixels in that tile and in case the newly drawn pixel that is belonging to this tile is calculated to be even close, you can just safely draw it.

You do not need to ask the "real" Z-buffer always now! All you need to ask this small resolution HiZ memory, that can be small-enough to be put on a fast SRAM chip near the rasterizer if this extra speed is needed. As you can see on the random presentation from net clearly also that at ATI they measured that around 60% the pixels always seem to pass a Z-test, so this new solution is a real speedup for this operation. What happens if the value is not closer than the earlier most close that is stored for that tile? Then we just ask the real Z-buffer the old-fashioned way, but this happens only 40% of the time.
I guess you see that storing this more "rough" depth buffer and operating on this one first does not take a lot of space and can help with speed. The bad thing happens if we need to access the Z-buffer through buses from the RAM.
I must add here that I got to know that not all cards have HiZ memory even if they are AMD cards and support HyperZ. For example my card has none of these, but I did not know about that myself so I have spent a lot of time debugging the code paths that do these things while it did not count at all for my issue.
Zmask RAM
Is the bandwith requirement still big whenever we need to access that Zbuffer? Use a fast and lossless compression on it so that we save bandwith was what they have surely thought at ATI offices!
They had to choose some compression that is both fast enough and good enough so instead of just using a random image compression method, they went on and created a specific lossless method just for Z compression.
This actually looks like a patented thing and if my information is right it is called DDPCM (Differential Differential Pulse Code Modulation) and is also talked about in this paper for example.
It is quite technical and we do not need to know all the details as most of this is already done in the hardware and not the driver, but the method makes use of tiling too: We use 4x4 or 8x8 sized micro tiles, but those can be tiled too and this is a way to compress all z-data of the tile in a lossless way in a few dwords.
An old comment of Marek from the source code tells us how:
/* My notes about Zbuffer compression:
*
* 1) The zbuffer must be micro-tiled and whole microtiles must be
* written if compression is enabled. If microtiling is disabled,
* it locks up.
*
* 2) There is ZMASK RAM which contains a compressed zbuffer.
* Each dword of the Z Mask contains compression information
* for 16 4x4 pixel tiles, that is 2 bits for each tile.
* On chips with 2 Z pipes, every other dword maps to a different
* pipe. On newer chipsets, there is a new compression mode
* with 8x8 pixel tiles per 2 bits.
*
* 3) The FASTFILL bit has nothing to do with filling. It only tells hw
* it should look in the ZMASK RAM first before fetching from a real
* zbuffer.
*
* ... (more details) ...
*
* 5) Each 4x4 (or 8x8) tile is automatically decompressed and recompressed
* during zbuffer updates. A special decompressing operation should be
* used to fully decompress a zbuffer, which basically just stores all
* compressed tiles in ZMASK to the zbuffer memory.
*
* 6) For a 16-bit zbuffer, compression causes a hung with one or
* two samples and should not be used.
*
* 7) FORCE_COMPRESSED_STENCIL_VALUE should be enabled for stencil clears
* to avoid needless decompression.
*
* 8) Fastfill must not be used if reading of compressed Z data is disabled
* and writing of compressed Z data is enabled (RD/WR_COMP_ENABLE),
* i.e. it cannot be used to compress the zbuffer.
*
* ... (more details) ...
Two bits for each 4x4 tiles? Of course there are just "not enough bits" to a full lossless compression of 4x4 tile depth values into 2 bits! This is why zero just indicate that it is cleared and there is uncompressed tile (when you need to once again go and run after the Z-buffer). The key is that the method uses that this is a geometry and that in many cases only a few triangles or one triangle is in the tile so instead of saving z buffer values, they can save "slopes" - basically the plane of the triangle represented as compressed as it can be. This mostly seem to work only if 1-2 triangles are in the tile so the compression is best in cases when the triangles are much bigger than the tiles. This is the case many times in FPS games if you see a big wall of a building for example.
Actually all of these compression methods are more complicated than how it is presented here and I only understand them the very small amount, but for going further it will be enough to know this is also using tiles.
The compressing and uncompressing of this memory into and from Zbuffer is just happening automatically in the background, but there might be need for a full uncompress sometimes (maybe when hyperZ gets to an other process?)
The compressed memory of this unit is called ZMASK RAM and my card has this, even though it does not have HiZ memory.
Fast Z clears
If you think about the above two tiling based methods, you actually get two pretty good ideas of fast zbuffer clearing. Both of them revolves around just setting the GPU to use the buffers and then only clear these smaller buffers instead of clearing the whole big ZBuffer. As far as reality goes for me it seems that the ZMASK RAM is the one that is used for this purpose.
Actually I think this is why they named the FASTFILL flag in the GPU register like that: because despite it does not fill anything, it tell the GPU to first look for Z-values in the compressed ZRAM. In a way this is what enables us to "seemingly fill the zbuffer" very fast with a given value as we can then just use this ZMASK RAM and set a slope that is perpencicular with the camera and is at the depth we desire.
This is the missing "detail" from the above text that is relevant:
* 4) If a pixel is in a cleared state, ZB_DEPTHCLEARVALUE is returned
* during zbuffer reads instead of the value that is actually stored
* in the zbuffer memory. A pixel is in a cleared state when its ZMASK
* is equal to 0. Therefore, if you clear ZMASK with zeros, you may
* leave the zbuffer memory uninitialized, but then you must enable
* compression, so that the ZMASK RAM is actually used.
Also the official r500 docs talk about ZB_CB_CLEAR too, which is using the
idle Z-buffer unit on the GPU to clear half the color buffer when the ZMASK
ram can be cleared the fast way so that unit is unused anyways.
The last missing comment details tells us this is not locking up in any ways:
* 9) ZB_CB_CLEAR does not interact with zbuffer compression in any way.
*
* - Marek
*/
Altough there is no interaction, it is still said that we better clear the color buffer using this faster way when we have the fast Z clear. Even if this works without the fast Z clear, there might be maybe waiting introduced?
Actually going more and more deep I might make errors here more and more so please do not expect everything is right how I am writing about these!
I did not check if the driver is not clearing the Zbuffer unnecessarily when the fast Z clear happens on the side, but I kind of think this is done well and there are no unnecessary operations. Actually I kind of think it can be optimized further, but it leads to no speed increase as no software ever used to really clear the color buffer except glxgears. See later.
Paying attention to the details
Okay, now we have a rough idea about what HyperZ is all about and how it work. With this knowledge (actually much earlier) you better start to look for the details when you see the glitches themselves.
As if pixels slowly rot away
The first thing I saw when running glxgears is that I can still see the gears turning in the first few frames - albeit glitchy - but every pixel that gets to be drawn kind of "gets used up". It is as if using a pixel would make that pixel rot away and not really usable anymore. This is not that simple as the same pixel can still light up, but with less and less chance.
I have figured that this problem actually persists if I stop running the app and restart it with same size (this is really easy to do with a tiling wm).
If you wait enough nothing is visible anymore just the top of the screen
What this hints for me? For me this hints that some kind of Zbuffer is not really gets erased well!
I have started up some games like Mount&Blade or Tux Racer and instead of the black color, what I saw was the background skybox or really far objects so surely the problem was with Z-buffering or HiZ or ZMASK or fast clear...
The upper third of the screen is always visible
This really came to my mind early as "one third of the screen". I did not really measure it, but it is so easily seen by naked eye that this is one third of the screen! For the first few moments this seems weird as 1/3 is not really a quite usual divider in computer graphics or computing. You would expect a half or a quarter screen corruption, but this stick into my mind that I felt is is a third.
I speculated that it is either some timing issue (think about how the screen draw lines - maybe missing some synchronization?) or some areas are not really enabled. An other and simple idea is that the buffers are erased but only too few bytes of some buffer is erased for some reason.
Resizing the screen fixes the problem
Just for a moment (for the next frame), but a window resize that also resize the backbuffer and zbuffer likely results in the gears showing up once again.
This kind of hint to me, that the problem is not with the real Zbuffer but with one of the new, optimized and smaller ones.
Seeing a macrotile in the glitch
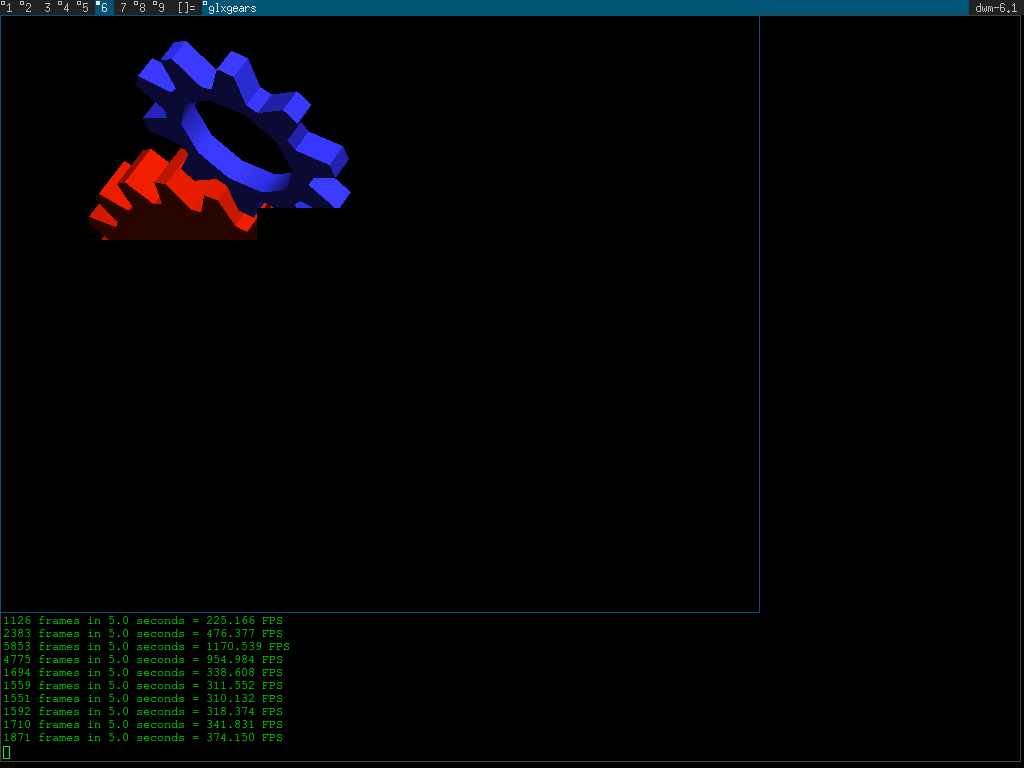
Look at this image I got when resizing! You can clearly see the 32x32 tile where the things start to get to look bad! It seems there are some number of tiles that we clear properly, then any further numbers are just uncleared and the junk just collects up in them with the time.
The first badly cleared macrotile is visible where the blue and red gears are meeting and you see this black "step-up". After this point, all macrotiles are badly cleared (or more likely - not cleared at all).
Debugging mesa r300 HyperZ driver code
Of course if you look at my bug report you will see that I was not doing my thinking or actions in the order being presented here, but looked up hard ATI docs for r300 registers (for my card) and r500 acceleration guide (which is not for my card, but close enough to r300) and just start hacking the mesa source code by grepping to the word "hyperz" in it!
The very first things after automatically "paying attention to the details" was to search the source code, then go for r300 registers. Back then I had no idea about HyperZ just that it is HiZ+compression+fast clears and I thought it must be all together or nothing (untrue as you see).
After grepping the source code of mesa, this is what I got (my own notes):
Hyperz related files:
HyperZ ownership is handled here:
src/gallium/drivers/r300/r300_context.c
src/gallium/drivers/r300/r300_context.h
Command stream writing happens here:
src/gallium/drivers/r300/r300_emit.c
Update is in here - this sets buffers to sends stuff
to card according to how docs say it:
src/gallium/drivers/r300/r300_hyperz.c
This is where hyperZ gets first activated:
src/gallium/drivers/r300/r300_blit.c
Register naming (closely remembers r300 and 500 docs):
src/gallium/drivers/r300/r300_reg.h
Here is the r300_setup_hyperz_properties(..):
src/gallium/drivers/r300/r300_texture_desc.c
Here is the gb_pipes query that returns 3 but should return one:
src/gallium/winsys/radeon/drm/radeon_drm_winsys.c
This list was in a simple text file through debugging and always grew. I am presenting this here if anyone ever needs to touch the code again to see what is stored where in the source code.
Aquiring HyperZ
Only one process can use HyperZ at a time, because this needs the small SRAM memori(es) that exists only once on the GPU. To help with this, HyperZ has ownership for one app and a random next app can automatically take ownership if the original HyperZ owner exits. There is no need to restart the app as it just "automagically works"!
It was really easy to find this code that does the aquire operation, because
I need to use this RADEON_HYPERZ=1 environment variable. I searched for where
it is accessed and I got the blit.c file and debug_get_option_hyperz.
You will not find this method directly as it is generated by a macro:
DEBUG_GET_ONCE_BOOL_OPTION(hyperz, "RADEON_HYPERZ", FALSE)
You better get ready to see macro usage as there are many in the mesa code. Not only simple macros to generate similar code (like to get env vars), but also things like the X-macro technique which is my personal favourite usage!
So after decyphering that the above macro creates debug_get_option_hyperz
you can finally find where it is called and see it is the r300_clear function.
This is where it happens:
/* If both depth and stencil are present, they must be cleared together. */
if (fb->zsbuf->texture->format == PIPE_FORMAT_S8_UINT_Z24_UNORM &&
(buffers & PIPE_CLEAR_DEPTHSTENCIL) != PIPE_CLEAR_DEPTHSTENCIL) {
zmask_clear = FALSE;
hiz_clear = FALSE;
} else {
zmask_clear = r300_fast_zclear_allowed(r300, buffers);
hiz_clear = r300_hiz_clear_allowed(r300);
}
/* If we need Hyper-Z. */
if (zmask_clear || hiz_clear) {
/* Try to obtain the access to Hyper-Z buffers if we don't have one. */
if (!r300->hyperz_enabled &&
(r300->screen->caps.is_r500 || debug_get_option_hyperz())) {
r300->hyperz_enabled =
r300->rws->cs_request_feature(r300->cs,
RADEON_FID_R300_HYPERZ_ACCESS,
TRUE);
if (r300->hyperz_enabled) {
/* Need to emit HyperZ buffer regs for the first time. */
r300_mark_fb_state_dirty(r300, R300_CHANGED_HYPERZ_FLAG);
}
}
/* Setup Hyper-Z clears. */
if (r300->hyperz_enabled) {
if (zmask_clear) {
hyperz_dcv = hyperz->zb_depthclearvalue =
r300_depth_clear_value(fb->zsbuf->format, depth, stencil);
r300_mark_atom_dirty(r300, &r300->zmask_clear);
r300_mark_atom_dirty(r300, &r300->gpu_flush);
buffers &= ~PIPE_CLEAR_DEPTHSTENCIL;
}
if (hiz_clear) {
r300->hiz_clear_value = r300_hiz_clear_value(depth);
r300_mark_atom_dirty(r300, &r300->hiz_clear);
r300_mark_atom_dirty(r300, &r300->gpu_flush);
}
r300->num_z_clears++;
}
}
This is quite a clever code as it first looks if we can use HiZ or Zmask or not at all (the stencil buffer uses bits from the zbuffer by storage so we cannot use fast clears if there is stencil otherwise it will be untouched).
After either the compressed Z or HiZ ram can be used and is available (the availability is also checked so hiz_clear for me is never true), we go and see if hyperZ is not enabled. If not enabled currently, we try to enable it immediately (so the first app calling clear gets the HyperZ when the owner gets closed) and mark the state dirty. These markings are necessary because there is a buffer with a first-dirty and last-dirty index that gets sent to the kernel radeon modules for updating real gpu command streams, ring buffers and whatever else so not marking things dirty mean as if you did not even do a write for the output registers or command streams. There are multiple atoms which seem to be the smallest atomic thing to send like this to the kernel level driver parts and to the GPU.
Clearing the buffers
There is no need to copy-paste the whole code from git here, but I want to give a pseudocode and some highlights about how clearing happens:
set_zmask_clear_and_hiz_clear;
try_to_aquire_hyperz;
set_zmask_depth_clear_value_if_needed? // KUL-A
cmask_clear?
CBZB clear setup? // KUL-B
clear_all_with_blitter? // KUL-C
clear_partial_with_tricks? // KULAKVA
Actually now I kind of feel that if the color buffer is cleared alongside the
fast Z clear, the driver is not optimizing out the usage of the blitter to
clear the the "real" Zbuffer. I am still unsure as I would need to dig deep
into the util_blitter_clear method but I have just realized it does not
really count because as the presentation from ATI says: basically never any
game clear the color buffer at all - all they do is to draw a skybox and just
clear the depth buffers and I know myself this is really the practice as even
I knew about it from my very young age on! It does not count if this is really
optimized or not as it never happen, just with glxgears likely ;-).
Here first I have spent a lot of time to figure out I am not having HiZ at all.
My first idea was to add a whole bunch of fprintf(stderr,..) codes to see
what kind of code paths are taken.
This way is how I got to know that KUL-A, B and C is always taken, but the very last KULAKVA one is never. The last is only taken if there is no color buffer clear directly or the color buffer happens to have CMASK_RAM. This latter is a compressed color buffer and my card is not having that neither.
KUL is short for Hungarian word "Küldetés" (mission) and the letters are there to make each printf different.
Using gdb
At this point my friends pointed me why I am not attaching with gdb if this is the userland driver part? I asked myself too: why not?
Actually it is pretty easy to use gdb as you just need to build mesa with -g
and likely without optimizations (-O0) and start a random 3D app like glxgears
using the gdb glxgears usual command. Before starting the app, you should
set the breakpoint to a function (like: b r300_clear) and when gdb ask you
if you want to put a breakpoint whenever this function gets loaded from a so,
just answer yes - because likely this is not loaded yet at the program start!
From that on, gdb can just be used as usual! Nothing more special is needed!
This way I have found I have no HiZ ram - why the function returns false? It returns so as we read zero bytes of HiZ ram! - neither CMASK ram.
Checking HyperZ enablement
Not only in the souce code I was searching, but also in the r300 docs for the register mapping. You can see a lot of HiZ and HyperZ related registers and flags in there.
For enabling HyperZ (that sometimes they completely use interchangably with the HiZ term!) you need to set two units: the ZB Zbuffer and the SC scan converter units specific registers.
ZB:ZB_BW_CNTL and SC:SC_HYPERZ_EN
You can look these up in the r300 reg docs if you want, but you can just search for all the HyperZ and HiZ strings and even ZMASK and such. The manual tells a lot about how the GPU works under the hood and what registers to set for which graphics state (for example normal Zwrite on/off registers are also here and documented properly).
What is not documented here is which order you need to do these things and also there is no information here about command stream packages or general architecture about the card and its acceleration. It seems no such doc was ever released for r300 cards, but we are lucky that we have the r500 ones and actually several others directly for some r500 cards!
First I was really hesitant to read the r500 docs for an older card, but I ended up thinking that knowing something badly is still better than knowing nothing at all so I went into this doc just to see that itself the doc tells that it might be actually used to the "very similar" earlier r400 and r300 cards too and the changes are highlighted whenever they could do so.
This is really awsome because this document has a whole section for HiZ, the various tiling modes and their memory layout but very small info about zram.
The doc also has a full example initialization sequence for HyperZ and also it contains the command buffer packet descriptions and order informations!
Together with the r300 register docs, the r5xx acceleration guide and the marked parts of the source code really tells you what the driver does!
The real enablement of HyperZ happens in the r300_emit_fb_state(..) call.
The emit is just emitting the info, but the hyperz.c file contains an update
method for updating the hyperz state accordingly to the internal state and
that is also worthy to look at.
Weird things
At this point on one day things just started to work... magically... I did not really do any relevant changes just some restarts and building with less compiler optimization. It went well for a whole day, but then got wrong once again right after that! Also an other guy came to the bug report who has the same 200M kind of card and has no issues (at least at the moment).
Weird and really gives a bad feeling so far! I was even thinking about bad HW!
Where is HiZ dword set to zero
I had luck of not understanding that my card intentionally does not have HiZ RAM so I went and looked what makes it return zero bytes there.
This is how I found this function:
src/gallium/drivers/r300/r300_texture_desc.c:r300_setup_hyperz_properties(..)
...
402 /* Check whether we have enough HIZ memory. */
403 if (hiz_numdw <= screen->caps.hiz_ram * pipes) {
404 tex->tex.hiz_dwords[i] = hiz_numdw;
405 tex->tex.hiz_stride_in_pixels[i] = stride;
406 } else {
407 tex->tex.hiz_dwords[i] = 0;
408 tex->tex.hiz_stride_in_pixels[i] = 0;
409 }
...
I actually went and looked up even all these strides and stuff as who knows what kind of setup value can be bad. A stride is also something that can cause bad glitches if badly set as it tells how to process the data per data rows.
With having gdb now I went and put a breakpoint here to see what the values are and I saw the reson why we do not have "enough" HiZ memory is because we literally have zero bytes! Above this, there is a similar code for zmask ram and there I saw we have zmask RAM memory but the driver thinks (rghtfully as later I grew to understand) that I have no HiZ. These values actually are coming from the kernel driver part once again.
Enabling ctags
I like to use vim as my main editor, but at this point it became a good idea to finally be able to easily "jump to definition" and such. This is really simple and useful but I always forget the very simple commands so I have this bash function for it. I share it with those who might not know this.
# CTAGS (mostly as a memo as the original command is shorter)
dev_ctags_setup() {
ctags -R
echo "Use ctrl+] and ctrl+t in vim. See help ctags."
}
This creates a tags file for editing souce codes in the current directory. This is useful a lot. An other good stuff is cscope and similar tools.
As you can see it integrates well with vim, but if you make a lot of changes you will sometimes need a tags database rebuilding. It is much faster than a full-blown background compiler and CTRL+N and such simple completion works for all opened tabs anyways so you barely need a rebuild while working.
Sorry for sidetracking, but this is what you do if you get stuck - you are sidetracking too and give some time for new ideas to come!
Trying to enable cmask
I saw if we have cmask, then we never end up using the blitter (likely), but a faster color buffer clearing method with cmask. This actually only made for MSAA use cases so that MSAA multisampling is not that awful slow...
You can run glxgears -samples 4 to test these kind of things (6 is the most
high value that works for me) and I added the hack to ensure cmask usage.
This is what I got:
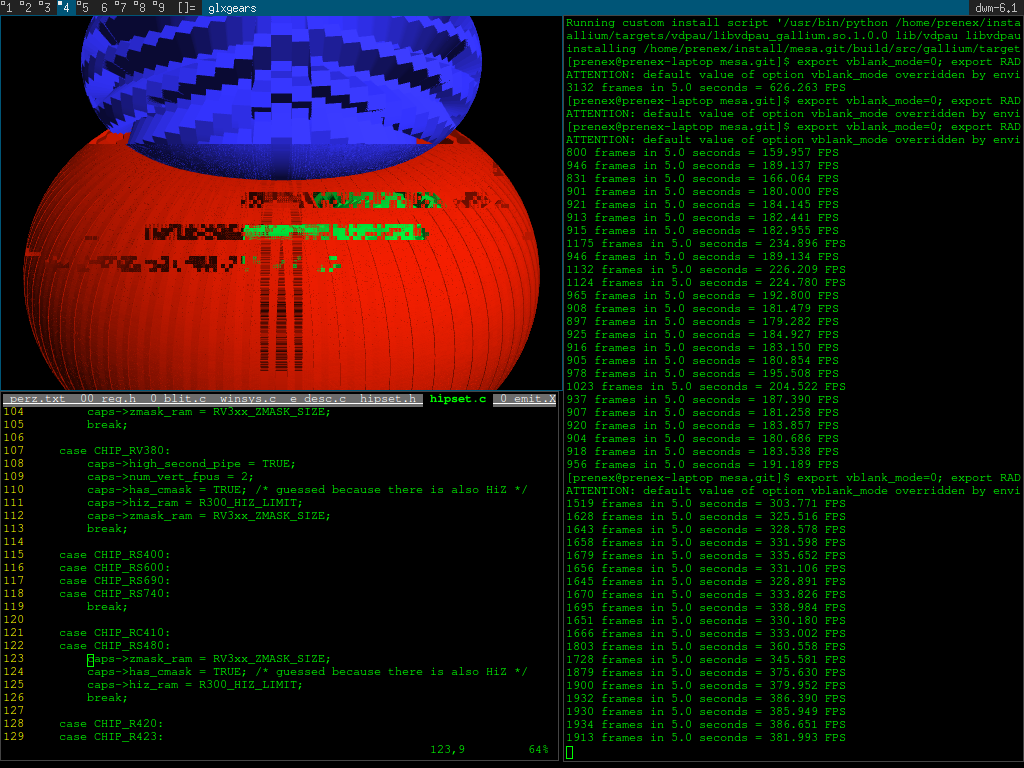
As you can see this way the driver thought I have the cmask unit and ram and tried to clear the color buffer that other way but this way we ended up not deleting it. After this experience there was a short period while I thought that maybe something is enabled that does not work - and similarly the code ends up not doing what works (just for the depth buffer). This made me lost a bit more time and actually a bit more morale, but I read out all docs again.
The "Mágus approach"
So I went back and forth, read out all docs and looked for any possible error but I must say I was quite stuck at this point so I went and used the "Mágus" approach - which is similar to "Bogus" approaches, just it involves good faith and hope in God instead of "just randomly trying to find a relevant place for changing the code with a measurable effect". :D :D :D
Okay where is anything that can indeed look similar-enough to affect the delete length of these tricky buffers? Especially the ZMASK RAM as the HiZ does not even seem to be in use?
379 /* Get the ZMASK buffer size in dwords. */
380 zcomp_numdw = r300_pixels_to_dwords(stride, height,
381 zmask_blocks_x_per_dw[pipes-1] * zcompsize,
382 zmask_blocks_y_per_dw[pipes-1] * zcompsize);
This seems to be an awsome place is not it? They say this calculates the size!
This function is just calling this code:
return (util_align_npot(stride, xblock) * align(height, yblock))
/ (xblock * yblock);
Which in turn calls this:
/**
* Works like align but on npot alignments.
*/
static inline size_t
util_align_npot(size_t value, size_t alignment)
{
if (value % alignment)
return value + (alignment - (value % alignment));
return value;
}
Also the zcompsize is calculated like this:
374 /* The 8x8 compression mode needs macrotiling. */
375 zcompsize = screen->caps.z_compress == R300_ZCOMP_8X8 &&
376 tex->tex.macrotile[i] &&
377 tex->b.b.nr_samples <= 1 ? 8 : 4;
I thought maybe this is wrong? But hey! Who cares what is wrong just try some random changes to see if it affects the "still good area" size on the screen!
I just went Mágus and changed like this:
379 /* Get the ZMASK buffer size in dwords. */
380 zcomp_numdw = r300_pixels_to_dwords(stride, height,
381 zmask_blocks_x_per_dw[pipes-1] * zcompsize * 2,
382 zmask_blocks_y_per_dw[pipes-1] * zcompsize * 2);
I thought this will make the "good area" bigger MAYBE. To my surprise this actually made the area around quarter of its size - to a very small thing line!
You can do the math: 2*2 = 4 and we multiplied both component sizes. What if
we divide by two instead? This was the first moment I saw a HyperZ setup
working on my machine - albeit really hacky ways!
The quickfix
Okay this was clearly a big hack, but how can we make up a meaning for this?
As you might already guessed, the fast Z clearing happens per-tile. By telling the above function that the xblock and yblock sizes are bigger the driver does issue fewer tile erasure so the "good area" shrink even further. When I divide these values to their half then the driver issues more tile erasure. Simple is just like that!
Okay we understand what happens, but how to fix this at least just a bit more properly? I went and looked around the source code, but even from the first moment the "pipes" parameter seemed to be really stricking for me! As you can see this is used as an index in a lookup table.
Look at this code:
/* The tile size of 1 DWORD in ZMASK RAM is:
*
* GPU Pipes 4x4 mode 8x8 mode
* ------------------------------------------
* R580 4P/1Z 32x32 64x64
* RV570 3P/1Z 48x16 96x32
* RV530 1P/2Z 32x16 64x32
* 1P/1Z 16x16 32x32
*/
static unsigned zmask_blocks_x_per_dw[4] = {4, 8, 12, 8};
static unsigned zmask_blocks_y_per_dw[4] = {4, 4, 4, 8};
Also look at this comment, even though it seems to affect HiZ only:
/* In HIZ RAM, one dword is always 8x8 pixels (each byte is 4x4 pixels),
* but the blocks have very weird ordering.
*
* With 2 pipes and an image of size 8xY, where Y >= 1,
* clearing 4 dwords clears blocks like this:
*
* 01012323
*
* where numbers correspond to dword indices. The blocks are interleaved
* in the X direction, so the alignment must be 4x1 blocks (32x8 pixels).
*
* With 4 pipes and an image of size 8xY, where Y >= 4,
* clearing 8 dwords clears blocks like this:
* 01012323
* 45456767
* 01012323
* 45456767
* where numbers correspond to dword indices. The blocks are interleaved
* in both directions, so the alignment must be 4x4 blocks (32x32 pixels)
*/
Hmm. So it seems that if you have multiple pipes, you will not only delete one block or tile at a tile but multiple ones! With two pipes you clear two at the same time and with four tiles you clear four. Hey! What is my pipes number?
With gdb I have found out mine is "3". If you look at zmask_blocks_?_per_dw
varible you can see that this is 12 and 4. The higher value leads to
a smaller "still good area" here so I should have a smaller value!
I tried to force a pipes number of 2, then as that just raised the "still good area" to half the screen I went further and forced "pipes=1",
Aaand Yes... this is why the good area was 1/3 of a screen! Because it was thinking I have pipes=3 here while I should only have pipes=1 here! I had no idea how once it worked before randomly though! That really bugged me...
At least I had a quickfix and could enjoy full 460 FPS in glxgears and 10% more FPS in Tux Racer while Urban Terror sometimes now going up to 150 FPS if I am staring at a wall up close and not doing anything (irreal thing to do in a 3D shooter of course - usually still 30-60 FPS).
This was the fix:
357 if (screen->caps.family == CHIP_RV530) {
358 pipes = screen->info.r300_num_z_pipes;
359 } else {
360 pipes = screen->info.r300_num_gb_pipes;
361 /* FIXME: Quickfix only for Mobility Radeon Xpress 200M in asus laptop!
362 pipes = 2; // Half the screen is bad for me
363 pipes = 1; // Whole screen is ok for me*/
364 }
As you can see we always got to use screen->info.r300_num_gb_pipes.
This is set in the radeon_drm_winsys.c:do_winsys_init(...) function:
385 if (ws->gen == DRV_R300) {
386 if (!radeon_get_drm_value(ws->fd, RADEON_INFO_NUM_GB_PIPES,
387 "GB pipe count",
388 &ws->info.r300_num_gb_pipes))
389 return false;
Hoppla, this is coming from the kernel side of the things! Just to clean it up, I have changed this here:
384 /* Generation-specific queries. */
385 if (ws->gen == DRV_R300) {
386 if (!radeon_get_drm_value(ws->fd, RADEON_INFO_NUM_GB_PIPES,
387 "GB pipe count",
388 &ws->info.r300_num_gb_pipes))
389 return false;
390 // FIXME: only works for my own setup (prenex):
391 ws->info.r300_num_gb_pipes=1;
Looking around the kernel modules
Marek appeared at this point and told no one really remembers how HyperZ works on r300 cards likely, but he can aswer basic questions if needed. He was thus answering literally faster where to look for these values in the kernel side than a grep -R haha and not only that, but even spotted what is the possible core problem on the side of the kernel.
Comment: Marek Olšák 2019-06-15 02:31:51 UTC
The problem might be in the kernel. See function rs400_gpu_init.
I think it should call r300_gpu_init instead of r420_pipes_init.
Indeed that is actually what ended up as the final fix so far just added by me.
Of course first I tested the solution and also checked dmesg logs that indeed
printed 3 pipes. The thing is that an RS400 gpu is not really an r400 kind,
but there is some kind of marketing naming bullshit going on so it would be
easily confusing to think that RC410 (which is RS400 it seems) is closer to
the r400/420 cards than r300 while these are basically r300 cards with a very
very few amount of extras. Mesa codes usually treat them is_rv350, but not as
is_r400 or any above that kind of stuff.
The r420_pipes_init call uses a register reading to read out the gb_pipes_num.
The older r300_init code uses hardwired values however and my card ends up to
use 1 pipes as it should happen anyways.
The proper fix
Before clearly deciding what to do, I had one more idea to discuss, namely
that there was a point in the r420_pipes_init where one can add extra override
values using if (rdev->pdev->device == 0x5a62). This would however only ever
fix things for my very own 200M kind of card.
Also after looking and looking around the naming of cards and how they relate (which was much harder to find info about than it seems) I think we ended up just agreeing more and more that these cards should be initialized as r300.
This seems to be the proper fix and now it is sent for the kernel source tree for people to discuss. They will either send it back or accept it into the radeon kernel modules.
For all of my tests the result is very stable, there are no performance issues whatsoever - but performance is actually even better this way. Some games gain 10%, some gain a bit more performance when this is turned on, but as I told you all, my card does not have HiZ RAM so others might gain more speedup actually on a "real" (non-mobile) r300 when this is turned on.
Also from dmesg logs we have found that the guy who has the same card gets to read the proper 1 pipe number from the registers - but likely because of luck!
There is a good chance that for some reason and one day, my card also returned the good value earlier, but this seems fragile and maybe just literally luck!
Actually as it turns out, HyperZ code was completely good, but the pipe init was completely bad. This is not what I expected, but good to be fixed!
Future possibilities
If anyone still has any problems, with r300 I would highly suspect that it is happening in the code paths that my card cannot take: My missing HiZ RAM or CMASK ram and such things having some issuefor them.
It might be also beneficial to maybe do some piglit testing (I have never done anything like that) so that maybe this HyperZ can be tried to be enabled in the feature matrix as a green feature.
I think I should not forget to add palemoon to the blacklist of 3D apps never using HyperZ just to be sure as firefox is there, but I use PM nearly always.
Also I have some dirty r300 (or common radeon?) graphical glitches on my rader especially a dirty one that makes textures corrupted in the Total War games. This might be a target for a future r300 analysis of mine actually...
Thanksgivings and stuff
Special thanks go for the following people any anyone I accidentally have missed out:
- Marek Olšák for being not only faster than light, but faster then me grepping/digging the kernel source ever.
- Everyone from Phoronix for their nice last article (not only about my stuff, but Rui's too)
- My friends rlblaster and aratvic (Zoltán aka zogi) for discussions through gmail and reading my very long status reports despite it did not effect them. Also that I got to know zogi contributed to r600 earlier without me even knowing about it.
- All family and friends who is okay with me going into the deep waters for weeks and talk less :-)
- Everyone with nice emails
- Everyone who ever contribute to open source stuff even the smallest amounts!
I cannot help, but put out the "hackerman" picture despite it took me a few days now and still got help in the end. Still I hope documenting all of this might help others and also make other people consider contributing to open source software. Not necessarily video drivers and such, but if you just add in the efforts and accept / ask for help when needed, you can do this too ;-)
I have no idea how long I am fixing around things in mesa, but it was and is a nice journey so far. Please forgive me if I use "fixing" and "debugging" in an interchangable way sometimes, but what counts is that in the end we get a much better software for everyone's delight. Just imagine how many hundredths of thousands or million commits are out there and imagine that many of them have at least around this amount - or even much higher effort - and still going!

Tags: drm, hyperz, r300, radeon, linux, kernel, mesa, arch, 32bit, linux, debug, glitches, fix, contribute, open-source, graphics, stack, analysis, 3D, optimization, tutorial, system, internals, hackerman, opengl, zbuffer, hiz, zmask, documentation